
Sanemäärä tarkoittaa yksittäisten sanaesiintymien eli saneiden kokonaislukumäärää valitussa aineistossa. Tällä sivulla on yleisiä ohjeita Kielipankin aineistojen sanemäärien laskemiseen.
Huomaa, että aineiston annotaatio- tai litterointiperiaatteet voivat vaikuttaa tuloksiin, etenkin jos korpuksen varsinaisen sisällön (esim. litteroidun tekstin) joukossa on kommentteja tai muita merkintöjä. Koska sanemäärän laskentatapa on usein korpuskohtainen, siitä on hyvä tehdä muistiinpanoja ja kuvata se tarvittaessa julkaisujen yhteydessä.
ELANissa on mahdollisuus käyttää samankaltaista hakua kuin käytöstä poistuneella LAT-alustalla.
| Valitse ELAN-ohjelman Search-valikosta komento Structured Search Multiple eaf… |  |
|
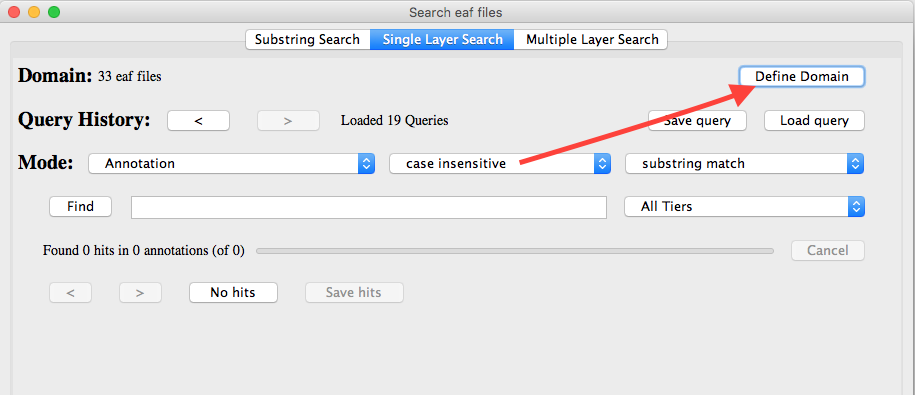
Näkyviin tulevassa ikkunassa on kolme välilehteä: Substring Search, Single Layer Search ja Multiple Layer Search. Valitse sanemäärän laskemista varten Single Layer Search. Ennen haun aloittamista on määriteltävä hakualue eli se aineisto, johon haluat haun kohdistaa. Klikkaa Define Domain. |
 |
|
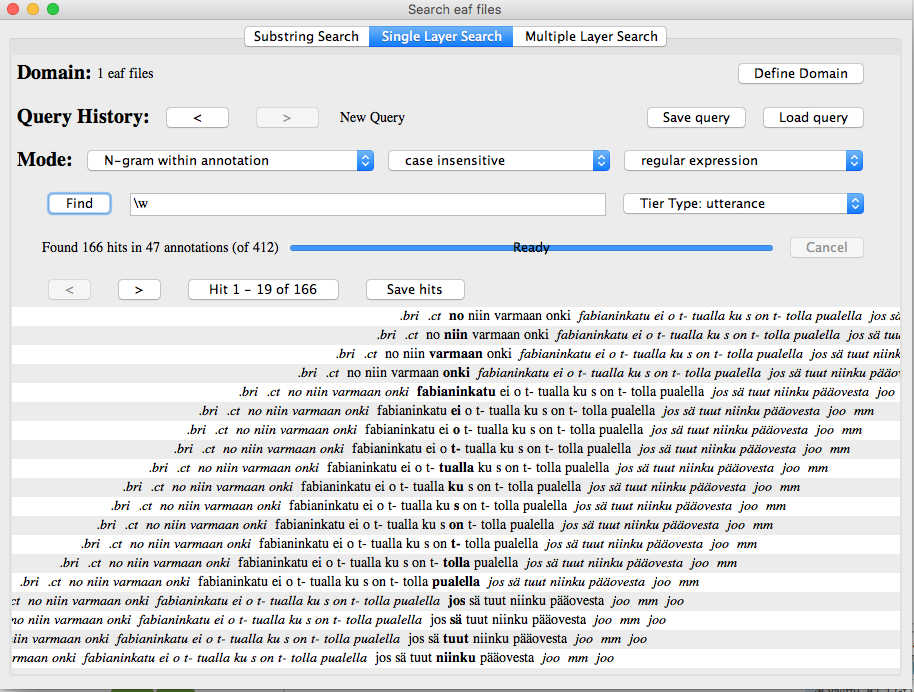
Valitse kohdassa Mode: vaihtoehdot ”N-gram within annotation”, ”case-insensitive” ja ”regular expression”. N-gram within annotation -valinnalla sanaesiintymät saa laskettua myös yksittäisen annotaation sisältä, jos annotaatio on monisaneinen. Regular expression -valinta tuo käyttöön ns. säännölliset lausekkeet. Kirjoita Find-hakukenttään \w Valitse hakutekstikentän oikealla puolella olevasta valikosta ne kerrokset tai kerrostyypit, jotka haluat mukaan laskelmaan. Huom. Sopiva valinta on korpuskohtainen, ts. sinun on ensin tiedettävä, mitä annotaatiokerroksia korpus sisältää ja kuinka ne on mahdollisesti tyypitetty. Esimerkiksi Reitti A-siipeen -korpuksen kohdalla voi valita ”Tier type: utterance”, jolloin saneet etsitään yhdellä kertaa niistä kerroksista, jotka sisältävät (kumman tahansa puhujan) puheen litteraatin. Esim. Helpuhe1-korpuksessa voi laskea erikseen ensin speech-tyyppiset kerrokset (=haastateltavien puheen litteraatit) ja sitten interviewer speech-tyyppiset kerrokset (=haastattelijoiden puheen litteraatit). Näiden summa kertoo aineiston kokonaissanemäärän. Klikkaa lopuksi Find ja odota hetki, niin kokonaissanemäärä ilmestyy tekstikentän alapuolelle, Ready-tekstin viereen. Esimerkiksi tulos 166 hits in 47 annotations tarkoittaa, että valitusta aineistosta löytyi 166 sanetta (yhteensä 47 annotoidussa puhunnoksessa tai muussa litteroidussa pätkässä). |
 |
(Ohje tulossa)



