
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 358720
Start date: 2024-01-01
Duration: 24 months
Report author: Jussi Piitulainen (UHEL)
WP 1.1: Report on Ingesting new unstructured resources
Date of reporting: 2024-11-28
Contributors: Jussi Piitulainen, Jyrki Niemi, Jack Rueter, Erik Axelson, Ute Dieckmann, Mietta Lennes, Tommi Jauhiainen (UHEL), Sam Hardwick, Martin Matthiesen (CSC)
Deliverable location: https://www.kielipankki.fi/corpora/
Keywords for the deliverable page: conversion; annotation; interoperability; VRT; UralicUD; Korp; Mink
The Language Bank of Finland receives and obtains text resources in different formats ranging from plain text documents to text enriched with complex annotations and document-level metadata. We aim to ensure that the material is made available to researchers in formats that are usable and interoperable. For text corpora, the Language Bank particularly supports and promotes VRT (VeRticalized Text) as an interchange format by developing, maintaining and utilizing the set of open-source VRT Tools for converting, enriching and ingesting resources containing text. All currently supported formats can be found via the Standards Information System of CLARIN.
The Suomi24 resource group was extended with the discussions from the years 2021–2023 (The Suomi24 Corpus 2021-2023, VRT version, and The Suomi24 Sentences Corpus 2021-2023, Korp version). Moreover, the entire The Suomi24 Sentences Corpus 2001-2023, Korp version and The Suomi 24 Corpus 2001-2023, VRT version now include named-entity and identified-language annotations. The Ylenews resource group was also extended with material from the years 2022-2024, which was made available for download (Yle Finnish News Archive 2022-2024, source). The Korp version of this extension will be published soon.
The Language Bank contributes to the Universal Dependencies (UD) project in order to maintain validity and coverage of the treebanks not only for Finnish but also more generally for Finnic, Finno-Ugric and Uralic languages (Uralic UD). Samples of languages in these groups will also be included in the text resources licensed by the Institute for Bible Translation and in other multilingual text collections that are currently being processed for publication.
In addition to other corpora, the Language Bank participated in publishing several resources prepared by the Ancient Near Eastern Empires (ANEE) research group, including Oracc, Achemenet and Babylonian Administrative and Legal Texts (BALT), available via Korp with linkage from their corresponding lexical networks.
The Trankit toolbox (see Nguyen et al. 2021), a recommended replacement for the old dependency parsers by the Turku NLP group, was installed in the CSC Puhti environment. Trankit was tested to be robust for the kind of morpho-syntactic annotation of pre-segmented Finnish that we need for the existing KLK and Suomi24 corpora. Once adapted for the CWB-VRT format, Trankit would be used to re-annotate the existing corpora with the Universal Dependencies (UD2) features and dependency syntax. Trankit could also be adapted for the segmentation of paragraphs into sentences and tokens, and it adds support for many other languages apart from Finnish.
The Mink platform, developed by Språkbanken Text in Sweden, was test-installed by the Language Bank. Mink allows users to process their own text corpora and to access the result via a private Korp instance. After the new version of the Korp platform is officially published at the Language Bank, it will be possible to make Mink available for wider use by the community. Support for user authentication in Mink is to be added in the year 2026.
The Language Bank participates in the recently launched CLARIN PressMint project that aims to compile a multilingual, comparable, annotated, translated and interoperable set of corpora of European historical newspapers by using a common TEI format. For PressMint, we will transform the out-of-copyright data from our existing KLK corpora (newspapers and magazines from the National Library) from the CWB-VRT format to the appropriate TEI format.
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Academy of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Research Council of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 5.1: Report on Educational resource development
Date of reporting: 24-11-2025
Report authors: Sanna Kumpulainen, Anna Sendra Toset (Tampere University)
Contributors: Inés Matres (University of Helsinki)
Deliverable location: https://doi.org/10.5281/zenodo.17696184
Keywords: digital tools, materials and/or best practices; educational resources; other supports; courses
The main objective of this deliverable is to provide an updated report on the educational resource development in DARIAH-FI for the 2024–2025 funding period. Available through Zenodo (https://doi.org/10.5281/zenodo.17696184), the report is divided into four sections:
To create this deliverable, we held several discussions throughout the 2024–2025 funding period, including two preliminary sessions during the DARIAH-FI online meeting of February 2025 and the FIN-CLARIAH meeting of June 2025 and one internal workshop on educational resource development at the end of October 2025. In this internal workshop, all local offices presented their updates on educational resource development for the 2024–2025 funding period and participated in a discussion on the next steps in DARIAH-FI for the 2026–2029 funding period.
The information on educational resource development described in the report is also maintained through the DARIAH-FI information platform, both in terms of training materials for the digital tools, materials and/or best practices of the facility (available at: https://www.dariah.fi/resources-2/) as well as degree programmes and regular courses offered at each local node (available at: https://www.dariah.fi/training-and-teaching/).
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Research Council of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 2.4: Report on Initializing terminology collections
Date of reporting: 21-11-2025
Report author: Harri Kettunen (UHEL)
Contributors: Tiina Onikki-Rantajääskö (UHEL)
Deliverable location: The Helsinki Term Bank for the Arts and Sciences – Tieteen termipankki
Since the last report in the autumn of 2024, 4,336 new concept pages have been created at the Helsinki Term Bank for the Arts and Sciences (HTB) in the following 37 fields: Anthropology, Archaeology, Art History, Automation and Control Engineering, Biology, Biosensing and Bioelectronics, Biotechnology, Bioproduct Technology, Botany, Business & Economics, Chemical Engineering, Classical Studies, Computer Science, Electrical Engineering, Geology, History, Integration of science, Law, Linguistics, Literary Studies, Materials Science, Mathematics, Mechanical Engineering, Media and communication studies, Mesoamerican Studies, Nutrition Science, Open Science, Philosophy, Photonics and Nanotechnology, Physics, Political science, Product Development, Sensory Science, Spatial Planning and Transportation Engineering, Sustainability Science, Theology, and Translation Studies. Furthermore, numerous updates have been made to the database on each field. In addition, the fields of Arctic Research and Geography are working offline until there is a critical mass of terminology to be published at the HTB.
The total amount of concept pages as of November 22, 2025, is 46,353
HTB has also been working in close cooperation with the Institute for the Languages of Finland (Kotus) on the names of languages of the world. In 2024–2025 we have had ten meetings with Kotus (Elina Wihuri and Ulla Onkamo), along with the consultant of the project, Lyle Campbell (Emeritus Professor, Department of Linguistics, University of Hawai’i at Mānoa). The work continues in 2026 with the aim to cement names of 7,900 languages of the world in Finnish.
In 2024 we also started to develop semi-automated processes for detecting terms and their relevant definition contexts, continued in 2025.
Starting in January 2025, Aalto University has had a directive in which all doctoral students must ensure that the key terminology of their doctoral thesis is also available in Finnish and/or Swedish. This terminology work is now being implemented at the HTB, adding to the growing number of new fields in the database.
In 2025, HTB has had presentations and other activities at the following conferences, seminars, and other events:
Conference presentations:
In November 2025, HTB conducted two surveys: one targeting users and another aimed at content experts. Both surveys closed on 21 November. We received 436 responses to the user survey and 53 responses to the expert survey. For comparison, the previous survey was conducted in 2019, when the corresponding figures were 236 for the user survey and 56 for the expert survey. Because the survey deadline fell on the same day this report was finalized, the results will be presented at a later date.
In October 2025 HTB received an award (kannustuspalkinto) from the Finnish Association for Scholarly Publishing (Suomen tiedekustantajien liitto), with the following statement:
“The award was granted to the Helsinki Term Bank for the Arts and Sciences as recognition for its work in promoting multilingualism and sense of community within science, as well as supporting the scientific vocabulary of the national languages. The board of the Finnish Association of Scholarly Publishers considers linguistic diversity in science and the careful explanation of concepts to be extremely important. Diversity and carefulness stand out in a time when national science policy rewards the use of English and the sheer number of publications. The Term Bank helps preserve the vitality and relevance of the national languages as languages of science. Moreover, carrying out the project through volunteer work strengthens the sense of community and networks across academic disciplines at a time when the significance of associations is generally diminishing in Finnish society.”[1]
Publications:
[1] “Kannustuspalkinto myönnettiin Tieteen termipankille tunnustuksena työstä tieteen monikielisyyden ja yhteisöllisyyden sekä kansalliskielten tieteellisen sanaston hyväksi. Suomen tiedekustantajien liiton hallitus pitää tieteen kielellistä diversiteettiä ja käsitteiden huolellista selittämistä erittäin tärkeänä. Diversiteetti ja huolellisuus korostuvat aikana, jossa kansallinen tiedepolitiikka palkitsee englannin käyttämisestä ja julkaisujen määristä. Tieteen termipankki vaalii kansalliskielten elinvoimaa ja ajantasaisuutta tieteen kielinä. Lisäksi toteutus talkootyönä tieteenalojen yhteisöllisyyttä ja verkostoja tilanteessa, jossa seuratoiminnan merkitys vähenee yleisesti suomalaisessa yhteiskunnassa.” https://tiedekustantajat.fi/tiedotteet/kannustuspalkinto-tieteen-termipankille-vuoden-tiedelehti-on-lahikuva
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Academy of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Research Council of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 5.1: Report on community engagement of multimodal societal data researchers
Date of reporting: 02-06-2025
Report authors: Sanna Kumpulainen, Anna Sendra Toset (Tampere University)
Contributors: Elina Late (Tampere University)
Deliverable location: N/A
The main objective of this deliverable is to widen the user base of FIN-CLARIAH by specifically targeting multimodal cultural heritage data researchers when organizing training workshops on different RI tools and data and conducting explicit user monitoring of the facility.
To this end, since the start of 2025 we hosted one training workshop for researchers on the resources of the facility in collaboration with other WPs and one dissemination event on the possibilities of conducting research with digital cultural heritage data:
Both activities happened online and required participants to be working with or be interested in cultural heritage data – thus complying with the aim of this deliverable. Given that community engagement should be continuous, it is previewed that more activities will be organized during autumn 2025.
Beyond the organization of these activities, members of Module 5 also took part in the online kick-off of the DARIAH-FI working group “Cultural heritage data and tools”, organized on February 26, where the goal was to establish a new working group dedicated to these resources and identify potential joint interests and collaboration opportunities.
Similarly, a publication related to research data management and data-intensive social sciences and humanities research was recently published. This publication, which also involved cultural heritage data researchers, highlighted the needs of scholars who conduct data-intensive social sciences and humanities research in relation to research data management. These results will be used by the RI to better consider the research data management needs of scholars who conduct data-intensive social sciences and humanities research. The publication can be found at:
Sendra, A., Late, E., Kumpulainen, S. (2025). From data lifecycle to research activity model: research data management in data-intensive social sciences and humanities research. Aslib Journal of Information Management, online first. https://doi.org/10.1108/AJIM-12-2024-0959
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Research Council of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Research Council of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
Report Author:: Sam Hardwick (CSC)
WP 1.3: Report on Tools and guidelines for video processing
Date of reporting: 15-05-2025
Contributors: Anni Järvenpää (CSC)
The foreseen impact the work package was
to make it easier for researchers to use, manage, annotate and share collections of video recordings as research data
To that end, we have provided software tools via the computational infrastructure of CSC (a FIN-CLARIAH member) and documentation through our Language Bank service.
CSC’s computational infrastructure has the potential to host quite large and computationally intensive video workflows:
Transfer speeds between these services is high. However, use of these systems for social sciences and humanities research is still developing. On HPC, we have ensured the availability and functioning of the audiovisual processing tool ffmpeg, the audio editing tool SoX and the audio feature extraction and classification suite openSMILE.
For AV-related software that is especially geared towards HSS users, our supported tools listing has articles for
To demonstrate combining multiple tools in a practical workflow, we wrote a hands-on tutorial for automatically adding subtitle tracks to video files containing speech. The tutorial combines ffmpeg, openSMILE, and LB’s own speech recognition API for Finnish, and it discusses video container formats and scripting a workflow with Python.
The FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Research Council of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Research Council of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 5.1: Report on evidence-based infrastructure development
Date of reporting: 17-12-2024
Report authors: Anna Sendra Toset, Farid Alijani, Jaakko Peltonen, Sanna Kumpulainen (Tampere University)
Contributors: Elina Late (Tampere University)
Deliverable location: The recommendation system is available through a GitHub repository
The main objective of this deliverable is to develop FIN-CLARIAH from a bottom-up perspective by collecting information on how the users interact with the tools and materials available in the RI, both implicitly (interaction log analysis) and explicitly (interviews, workshops).
PART A: IMPLICIT USER MONITORING
As for the implicit user monitoring, the goal is to design and develop methods that enable analysis of log data from systems in the FIN-CLARIAH infrastructure and are usable for other compatible systems. The analysis of log data can serve purposes such as monitoring use of the systems and for recommendation of content to end-users.
Firstly, as part of an earlier deliverable, we conducted a comprehensive study on the utility of the log data to investigate the feasibility of developing both user-based and item-based recommender systems which could be potentially deployed for end-users in the future.
Secondly, as a proof of concept we have developed a collaborative recommender system to assist information retrieval in digital libraries, based on log data gathered from use of the libraries. In the recommender system, we are currently using the National Library of Finland (NLF) dataset, including metadata of the collection, description, preservation and accessibility of Finland’s printed national heritage as digitized materials. The proof of concept is easily extensible to comparable log files of other digital libraries, and similar approaches can be applied to other DARIAH-FI collections. We have an open access GitHub repository for the public use (see Deliverable location) which has been primarily tailored to the SLURM clusters, provided by CSC infrastructures for data storage and massive computational resources.
The developed recommender system combines collaborative and content-based recommendation. It has been initially developed with similarity search approaches and is extensible to various inference schemes including neural approaches in future work. During the current research period we have further improved the operation of the recommender system by analysis of its behavior and identification and resolving of data quality issues, in particular resolving OCR issues by incorporating language and spell checking for Finnish, Swedish and English with public software. We have made it possible to deploy and run the system as a standalone system running on a suitable (virtual) server. We have further tuned the responsibility of the system to make it as fast as possible even on a large corpus. Moreover, we have greatly improved the user interface of the system to allow seamless interplay between the recommendations and the baseline NLF search engine without requiring manual back and forth switching from the user; we have further added information of search result counts and (as an optional future feature) of their time distribution.
We have demonstrated our recommender system in two research events to promote it for researchers and audiences alike:
We have further developed a testing scheme for quantitative evaluation of the performance of the system and users’ satisfaction with it. The procedure is suitable to be run across a series of user experiments, for comparing the new system to a baseline system, which is here the original NLF search system. Recruiting for running such experiments is underway.
PART B: EXPLICIT USER MONITORING
As for the explicit user monitoring, during November 2024 we launched a round of interviews specifically targeting Kielipankki users with the objective of evaluating how this service is supporting the research tasks of social sciences and humanities scholars. Particularly, the interviews focus on assessing the experiences of these researchers with Kielipankki as well as on identifying their perceived needs and expectations regarding this service. The round of interviews is currently ongoing, and we expect to have the first results during Q1/2025.
Other work related to the explicit user monitoring consisted of exploring research data management practices among scholars with experience in digital humanities and computational social sciences research to find ways of better supporting these practices. This study was presented in Informaatiotutkimuksen päivät 2024 (Turku, 6-7 November) and was submitted for publication during Q4/2024.
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Research Council of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 358720
Start date: 2024-01-01
Duration: 24 months
Report author: Jussi Piitulainen (UHEL)
WP 1.1: Report on Named-Entity Annotation
Date of reporting: 2024-09-26
Contributors: Jussi Piitulainen, Jyrki Niemi (UHEL), Sam Hardwick (CSC)
Deliverable location:
Keywords for the deliverable page: named-entity; finnish-nertag; VRT; Suomi24
Name-like phrases are annotated in the Suomi24 2001–2020 VRT corpus in the Language Bank of Finland, using the computational resources of CSC. The new annotations are the three formats of the finnish-nertag 1.6 tool: maximally long identified names, names nested in those, and the BIO (begin, inside, outside) format for the maximal names.
All 20 years have already been processed with the tool. A small number of triply nested annotations required correction, for which a post-processing tool was written. All years are pending the addition of structural markup tags for each maximal name.
The final annotations are expected to be available in the Language Bank both through the Korp search engine and as a new downloadable version of the corpus in October 2024.
As an example of the tag format, below is a VRT fragment (found in year 2010 data) where ”Turun hallinto-oikeudelle” is recognized as a maximally long name with ”Turun” as a shorter name nested inside. There can be even a third nesting level. (The example is a projection to just the word and the new fields. Base forms and other morpho-syntactic annotations remain.)
| word | nertag2 | nertags2/ | nerbio2 |
| joka | _ | | | O |
| jätetään | _ | | | O |
| Turun | EnamexOrgCrp-B | |EnamexOrgCrp-B-0|EnamexLocPpl-F-1| | B-ORG |
| hallinto-oikeudelle | EnamexOrgCrp-E | |EnamexOrgCrp-E-0| | I-ORG |
| ensi | _ | | | O |
| maanantaina | _ | | | O |
The number of maximally long names identified in the years 2001–2010 (roughly a half of the corpus) is as follows, by counting the BIO start tags (the B of BIO). The BIO tags classify the recognized names in six types, with a finer classification provided by the other formats.
| Start tag (BIO) | frequency |
| B-PER | 22 416 185 |
| B-PRO | 17 347 958 |
| B-LOC | 14 271 499 |
| B-ORG | 9 088 301 |
| B-MISC | 4 419 947 |
| B-DATE | 2 590 846 |
The annotation work was facilitated by writing a new preprocessing tool that hides from the finnish-nertag tool such input sentences that might, empirically, induce extreme resource consumption (usually excessive time, sometimes excessive space, both leading to a crash). Some of these sentences originate in trollish behaviour in the discussion forum, some are otherwise not really ordinary sentences at all. Some may have been segmented in a less than helpful way, possibly due to missing punctuation marks or missing spaces.
In addition to the names, the corpus was also annotated with HeLI-OTS 2.0 language identification of each sentence and summaries in paragraph and text elements.
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Academy of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 2.4: Report on Term definition discovery procedures
Date of reporting: 16-09-2024
Report author: Harri Kettunen (UHEL)
Contributors: Tiina Onikki-Rantajääskö (UHEL)
Deliverable location: The Helsinki Term Bank for the Arts and Sciences – Tieteen termipankki
Since the start of 2024, 309 new concept pages (terminology articles) have been created and updates have been made on 1,078 concepts to the database of the Helsinki Term Bank for the Arts and Sciences (HTB). New concept pages have been created in the following fields: Art History, Educational Sciences, Environmental Sciences, Geology, Linguistics, Martial Arts Studies, Mesoamerican Studies, Nutritional Sciences, Open Science, Philosophy, and Theology. The full amount of concept pages as of September 16, 2023, is 45,436.
Furthermore, updates have been made to the database on 1,078 concept pages in the following fields: Aesthetics, Biology, Botany, Educational Sciences, Folklore, Geology, History, Indigenous Studies, Language Technology, Linguistics, Literary Studies, Martial Arts Studies, Open Science, Performing Arts, Philosophy, Translation Studies, and Veterinary Medicine.
In addition, the fields of Anthropology, Studies, Gender Studies, Mathematics, and Urban Studies are working offline until there is a critical mass of terminology to be published at the HTB. Furthermore, terminology work has been agreed upon to be carried out in the following fields: Arctic Research, Asian Studies, Geography, Military Sciences, and Physiology. A multidisciplinary group has also been established for meta scientific terminology of transdisciplinarity.
In 2024, we have also started to develop semi-automated processes for detecting terms and their relevant definition contexts in valid academic text genre corpora such as E-thesis in cooperation with Antti Kanner and Jussi Piitulainen (UHEL).
Furthermore, HTB has started cooperation with Aalto University on the terminology of the fields of studies at Aalto. These will include the following, representing all the disciplines at the Aalto University: Civil Engineering, Energy Technology, Geoinformatics, Mechanical Engineering, Real Estate Economics, Spatial Planning and Transportation Engineering, Water and Environmental Engineering, Accounting, Business Law, Economics, Entrepreneurship, Finance, Information Systems Science, International Business, Logistics, Management Science, Marketing, Organization and Management, Organizational Communication, Chemistry, Biotechnology, Chemical Engineering, Processing of Materials, Materials Science, Bioproduct Technology, Neuroscience and Biomedical Engineering, Mathematics and Statistics, Systems and Operations Research, Engineering Physics, Computer Science, Industrial Engineering and Management, Automation and Control Engineering, Robotics and Autonomous Systems, Electronic and Digital Systems, Biosensing and Bioelectronics, Electrical Power and Energy Engineering, Electronics, Photonics and Nanotechnology, Radio Science and Engineering, Space Science and Technology, Signal Processing and Data Analytics, Acoustics and Speech Technology, Communications Engineering and Networking Technology, Interactive Systems, Art Education, Contemporary Art, New Media, Photography, Visual Communication Design, Visual Culture, Design, Film and Television, Costume Design, Architecture, and Landscape and Urbanism. HTB will coordinate a meeting with the Doctoral Schools of the Aalto University on October 3rd, 2024, to plan the implementation of terminology work for the future.
HTB has also been working in close cooperation with the Institute for the Languages of Finland (Kotus) on the names of languages of the world. During the first half of 2024 we have had four meetings with Kotus (Elina Wihuri and Ulla Onkamo), along with the consultant of the project, Lyle Campbell (Professor, Department of Linguistics, University of Hawai’i at Mānoa).
The coordinator of the HTB, in cooperation with the Teachers’ Academy of the University of Helsinki, organized a session on January 29th titled “Kansalliskielten asema korkeakouluopetuksessa” (“The role of national languages in higher education”), featuring the following presenters: Johanna Komppa (Senior University Lecturer of Finnish Language, UHEL), Tiina Onikki-Rantajääskö (Professor of Finnish Language, UHEL), Janne Saarikivi (part-time professor of Saami language, University of Tromsø), Mikko Laitinen (Professor of English Language, University of Eastern Finland), and Sirpa Leppänen (Emerita Professor of English Language, University of Jyväskylä).
HTB has also had presentations at the following conferences, seminars, and other events:
Publications:
Kettunen, Harri (2024). Monitieteisyydestä tieteidenvälisyyteen: Joukkoistaminen Tieteen termipankin terminologiatyössä. Sosiaalilääketieteellinen Aikakauslehti 2024: 61: 448–450.
Kettunen, Harri & Tiina Onikki-Rantajääskö (2024) Vetenskapstermbanken i Finland i samhällets tjänst. Språk i Norden / Sprog i Norden 2024. https://tidsskrift.dk/sin/article/view/144160
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Academy of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 358720
Start date: 01-01-2024
Duration: 24 months
WP 5.1: Report on community engagement of multimodal societal data researchers
Date of reporting: 20-08-2024
Report author: Sanna Kumpulainen, Anna Sendra Toset (Tampere University)
Contributors: Elina Late, Jaakko Peltonen, Farid Alijani (Tampere University)
Deliverable location: N/A
The main objective of this deliverable is to widen the user base of FIN-CLARIAH by specifically targeting multimodal societal data researchers when organizing training workshops on different RI tools and data and conducting explicit user monitoring of the facility.
To this end, since the start of 2024 we hosted two training workshops for researchers on the resources of the facility in collaboration with other WPs and organized two participatory workshops for improving services related to the RI, starting first with research data management. The events included:
Both training workshops required participants to be working with or be interested in social media data, while both participatory workshops required participants to be working with social media data and/or visual materials – thus complying in both cases with the aim of this deliverable.
Likewise, given that community engagement should be continuous, it is previewed that more training and/or participatory workshops will be organized during 2025.
Beyond the organization of these events, members of the WP 5.1 also took part in the in-person FIN-CLARIAH Meeting Helsinki organized on June 10, where the goal was to reflect on how SSH research will be affected by AI and how the RI should prepare for this.
FIN-CLARIAH project has received funding from the European Union – NextGenerationEU instrument and is funded by the Academy of Finland under grant number 358720.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 4.2: Report on Parliament of Finland Ontology
Date of reporting: 2023-11-09
Report author: Eero Hyvönen (Aalto University)
Contributors: Eero Hyvönen (PI), Laura Sinikallio, Petri Leskinen, Senka Drobac, Jouni Tuominen, Matti La Mela, Mikko Koho, Esko Ikkala, Minna Tamper, Rafael Leal, Heikki Rantala
Deliverable locations:
The Parliament of Finland Ontology with populated data and data services have been published Feb 14, 2023, using CC BY 4.0 license at the following platforms:
New declarative version of Sampo-UI framework used in the ParliamentSampo portal:
https://github.com/SemanticComputing/sampo-ui
Open online video lectures course.
https://seco.cs.aalto.fi/teaching/sw-introduction/index.html
Tutorial materials and video on using Sampo-UI frameworks for portal development:
https://seco.cs.aalto.fi/tools/sampo-ui/
2023
2022
2023
Senka Drobac, Laura Sinikallio and Eero Hyvönen: An OCR Pipeline for Transforming Parliamentary Debates into Linked Data: Case ParliamentSampo – Parliament of Finland on the Semantic Web. Digital Humanities in the Nordic and Baltic Countries Publication, DHNB2023 Conference Proceedings, vol. 5, no. 1, University of Oslo Library, Norway, 2023. bib pdf link
Eero Hyvönen: Parlamenttisampo avaa eduskunnan miljoona puhetta ja kansanedustajien verkostot kaikkien tutkittaviksi. Tieteessä tapahtuu, vol. 41, no. 1, Tieteellisten seurain valtuuskunta (TSV), 2023. bib pdf link
Eero Hyvönen, Petri Leskinen and Jouni Tuominen: A Data-driven Approach to Create an Ontology of Parliamentary Work: Case Parliament of Finland on the Semantic Web. Proceedings of SWODCH 2023. Semantic Web and Ontology Design for Cultural Heritage. Co-located with the 22nd International Semantic Web Conference (ISWC 2023) in Athens, Greece, CEUR Workshop Proceedings, Vol-3540, November, 2023. bib pdf link
Eero Hyvönen, Laura Sinikallio, Petri Leskinen, Senka Drobac, Rafael Leal, Matti La Mela, Jouni Tuominen, Henna Poikkimäki and Heikki Rantala: Plenary Speeches of the Parliament of Finland as Linked Open Data and Data Services. Joint Proceedings of the Second International Workshop on Knowledge Graph Generation From Text and the First International BiKE Challenge co-located with 20th Extended Semantic Conference (ESWC 2023), pp. 1-20, CEUR Workshop Proceedings, Vol. 3447, August, 2023. bib pdf link
Henna Poikkimäki, Petri Leskinen and Eero Hyvönen: Applying Network and Bibliometric Analyses to Mentions of Politicians in Plenary Speeches: Case ParliamentSampo – Parliament of Finland on the Semantic Web. August, 2023. Submitted for evaluation. bib pdf
Eero Hyvönen, Petri Leskinen and Heikki Rantala: Integrating Faceted Search with Data Analytic Tools in the User Interface of ParliamentSampo – Parliament of Finland on the Semantic Web. Proceedings of ESWC 2023, poster and demo papers, Sringer-Verlag, June, 2023. bib pdf
Eero Hyvönen: Creating and Using a National Linked Open Data Infrastructure for Cultural Heritage Applications and Digital Humanities Research: Lessons Learned. DARIAH Annual Event 2023, abstracts of papers, DARIAH-EU, June, 2023. bib link
Eero Hyvönen: Creating and Using a Linked Open Ontology and Data Infrastructure for Digital Humanities in Finland: Lessons Learned 2003-2023. June, 2023. Under review. bib pdf
Minna Tamper, Laura Sinikallio, Jouni Tuominen and Eero Hyvönen: Transforming Linguistically Annotated Finnish Parliamentary Debates Into the Parla-CLARIN Format. Digital Humanities in the Nordic and Baltic Countries Seventh Conference (DHNB 2023), Book of Abstracts (Sofie Gilbert and Annika Rockenberger (eds.)), pp. 118, University of Oslo Library, Oslo, Norway, March, 2023. bib link
Eero Hyvönen: How to Create a National Cross-domain Ontology and Linked Data Infrastructure and Use It on the Semantic Web. Programming and Data Infrastructure in Digital Humanities, Book of Abstracts, pp. 7, High Performance Computing Centre, University of Évora, Portugal, March, 2023. bib link
Eero Hyvönen, Petri Leskinen, Laura Sinikallio, Senka Drobac, Rafael Leal, Matti La Mela, Jouni Tuominen, Henna Poikkimäki and Heikki Rantala: ParliamentSampo Infrastructure for Publishing the Plenary Speeches and Networks of Politicians of the Parliament of Finland as Open Data Services. Aalto University, Dept. of Computer Science, February, 2023. Paper published at the publication event of the ParliamentSampo data service and portal. bib pdf
Eero Hyvönen: How to Create a National Cross-domain Ontology and Linked Data Infrastructure and Use It on the Semantic Web. Semantic Web – Interoperability, Usability, Applicability, IOS Press, 2023. Forth-coming. bib pdf
Eero Hyvönen: Digital Humanities on the Semantic Web: Sampo Model and Portal Series. Semantic Web – Interoperability, Usability, Applicability, vol. 14, no. 4, pp. 729-744, IOS Press, 2023. bib pdf link
2022
Henna Poikkimäki, Petri Leskinen, Minna Tamper and Eero Hyvönen: Analyses of Networks of Politicians Based on Linked Data: Case ParliamentSampo – Parliament of Finland on the Semantic Web. Semantic Web and Ontology Design for Cultural Heritage (SWODCH 2022), Turin, Italy, Proceedings, CEUR WS Proceedings, 2022. Accepted. bib pdf
Eero Hyvönen, Laura Sinikallio, Petri Leskinen, Matti La Mela, Jouni Tuominen, Kimmo Elo, Senka Drobac, Mikko Koho, Esko Ikkala, Minna Tamper, Rafael Leal and Joonas Kesäniemi: Linked Data Approach for Studying Parliamentary Speeches and Networks of Politicians in Finland 1907-2021 (long paper). Digital Humanities 2022, Conference Abstracts, July 25-29, 2022 Online, Tokyo. Japan, University of Tokyo, pp. 254-257, ADHO, July, 2022. bib link
Matti La Mela, Fredrik Norén and Eero Hyvönen (eds.): Proceedings of the Digital Parliamentary Data in Action (DiPaDA 2022) Workshop. CEUR Workshop Proceedings, vol. 3133, May, 2022. bib link
Eero Hyvönen, Laura Sinikallio, Petri Leskinen, Matti La Mela, Jouni Tuominen, Kimmo Elo, Senka Drobac, Mikko Koho, Esko Ikkala, Minna Tamper, Rafael Leal and Joonas Kesäniemi: Finnish Parliament on the Semantic Web: Using ParliamentSampo Data Service and Semantic Portal for Studying Political Culture and Language. Digital Parliamentary data in Action (DiPaDA 2022), Workshop at the 6th Digital Humanities in Nordic and Baltic Countries Conference, long paper, pp. 69-85, CEUR Workshop Proceedings, Vol. 3133, May, 2022. bib pdf link
Minna Tamper, Rafael Leal, Laura Sinikallio, Petri Leskinen, Jouni Tuominen and Eero Hyvönen: Extracting Knowledge from Parliamentary Debates for Studying Political Culture and Language. Proceedings of the 1st International Workshop on Knowledge Graph Generation From Text and the 1st International Workshop on Modular Knowledge co-located with 19th Extended Semantic Conference (ESWC 2022) (Sanju Tiwari, Nandana Mihindukulasooriya, Francesco Osborne, Dimitris Kontokostas, Jennifer D’Souza and Mayank Kejriwal (eds.)), vol. 3184, pp. 70-79, CEUR WS, May, 2022. International Workshop on Knowledge Graph Generation from Text (TEXT2KG 2022). bib pdf link
Matti La Mela, Fredrik Norén and Eero Hyvönen: Digital Parliamentary Data in Action (DiPaDA 2022): Introduction. Proceedings of the Digital Parliamentary Data in Action (DiPaDA 2022) Workshop, CEUR Workshop Proceedings, Vol. 3133, May, 2022. bib pdf link
Laura Sinikallio: Eduskunnan täysistuntojen pöytäkirjojen muuntaminen semanttiseksi dataksi ja julkaiseminen verkkopalveluna (Transformation of the Debates of the Parliament of Finland into Semantic Data and a Data Service. (in Finnish), University of Helsinki, Department of Computer Science, February, 2022. MSc Thesis. bib pdf link
Esko Ikkala, Eero Hyvönen, Heikki Rantala and Mikko Koho: Sampo-UI: A Full Stack JavaScript Framework for Developing Semantic Portal User Interfaces. Semantic Web – Interoperability, Usability, Applicability, vol. 13, no. 1, pp. 69-84, January, 2022. Online version published in 2021, print version in 2022. bib pdf link
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 5.2: Report on Educational material
Date of reporting: 29-11-2023
Report author: Sanna Kumpulainen (Tampere University)
Contributors: Sanna Kumpulainen, Jaakko Peltonen, Anna Sendra Toset, Elina Late, Farid Alijani (Tampere University)
Deliverable location: DARIAH-FI: Educational material
This deliverable is a living document that includes relevant information regarding the educational materials relevant to the DARIAH-FI research infrastructure and its resources, such as documentation created for helping use the different tools, datasets, and workflows, and guidance on which courses might be relevant to use the resources more efficiently. The document also includes an overview of the state of the digital humanities and computational social sciences education in Finland, including links to relevant courses and programmes at the bachelor, master, and doctoral level.
To create this deliverable, we used data from an internal survey on digital humanities and computational social sciences education in Finland conducted within the members of the DARIAH-FI research infrastructure, as well as information provided by the different work packages on their respective resources (e.g., location, related educational materials). Since some educational materials are still under development and have not been released yet, it is expected that the document will be made public during December 2023 through the DARIAH-FI website.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 5.1: Report on Protocol for collecting workshop data
Date of reporting: 29-11-2023
Report author: Sanna Kumpulainen (Tampere University)
Contributors: Sanna Kumpulainen, Jaakko Peltonen, Anna Sendra Toset, Elina Late, Farid Alijani (Tampere University)
Deliverable location: https://doi.org/10.5281/zenodo.10217404
The protocol for collecting workshop data is available at: https://doi.org/10.5281/zenodo.10217404
This document is intended to serve as an initial guide for collecting user experience data from workshops and training sessions related to the resources developed by the FIN-CLARIAH consortium. In this context, the deliverable includes recommendations for designing the study and for setting up the data collection process, as well as information for creating protocols, informed consents, and other similar documents related to collecting user experience data.
To create this document, we used data collected from semi-structured interviews (n=34) with potential end-users of DARIAH-FI conducted between September 2022 and February 2023, as well as information gathered via a selected narrative review of different resources related to research design. This deliverable must be read in conjunction with the specific instructions provided by the institutions where the studies that collect user experience data take place.
Note: An updated version of this document might be released during Q1/2024.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 4.3: Report on Representative Twitter dataset(s) of user-generated texts and metadata
Date of reporting: 25-11-2023
Report author: Mikko Laitinen (University of Eastern Finland)
Contributors: Masoud Fatemi, Mehrdad Salimi, Paula Rautionaho (all from the University of Eastern Finland)
Deliverable location: https://nordictweetstream.fi/ The URL is currently open for researchers, and we will add authentication to it in the spring of 2024.
The WP’s main objective was to develop a representative dataset of social media data from Twitter from the five Nordic countries. The underlying idea is that various social media applications offer a promising and extremely large source of data for a range of disciplines in social sciences and the humanities (SSH) today, but research activities are often hindered by the lack of technical knowledge in collecting, pre-processing and analysing very large datasets. During the funding period, we expanded the data collection substantially, when it because clear that the future of the data collection route became more and more uncertain. All the materials were collected during the period when the academic application programming interface of this social media platform was still open, and later on when the company changed its name to X, the API was closed down. In the hindsight, the decision to store large amounts of material from various geographic settings turned out to be a wise move, because this subproject has now saved 12.5 years of material for future research.
The project activities so far have consisted of two parts:
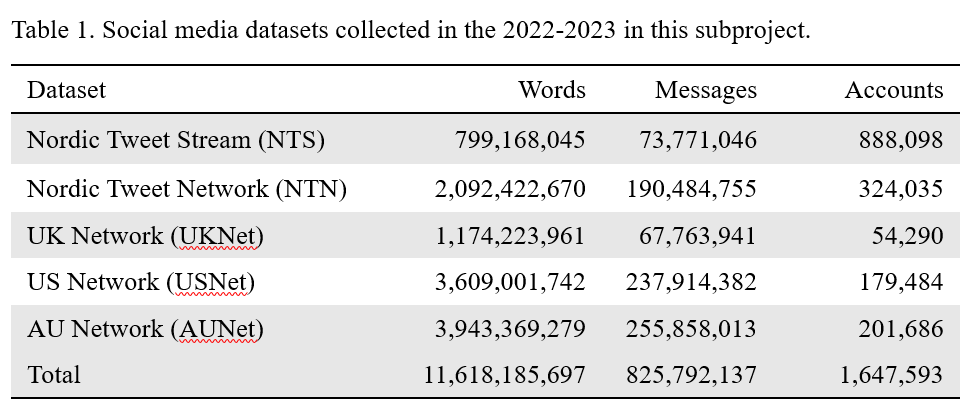
This WP has reached its objectives and succeeded in creating a national niche within the Finnish DH sphere. We have a good team that combines expertise from sociolinguistics and computer sciences, and we are able to develop digital tools for a range of audiences.
For 2024–2025, we aim at continuing the work, and adding a graphic interface for accessing network information and combining this network information with textual searches.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 2.5: Report on Finnish as a second language learners automated analysis and annotation tools
Date of reporting: 28-11-2023
Report author: Ari Huhta (University of Jyväskylä)
Contributors:: Jenny Tarvainen, Ida Toivanen, Sirkku Kronholm, Mika Halttunen (University of Jyväskylä)
Deliverable location: (so far only in Google Drive)
Work in WP2.5 divides into two stages. In 2022, tools used for automated analysis of texts written by native speakers of Finnish were reviewed in collaboration with WP3.2. To investigate how the tools perform with texts written by Finnish as second language (L2) learners’ texts, texts collected in previous projects were used to test certain tools. The texts represented different proficiency levels defined in the Common European Framework of Reference for Languages (CEFR), based on assessments by trained raters.
Testing focused on two promising tools, Finnish Tagtools (Language Bank) and Turku-neural-parser-pipeline. Both tools utilize machine learning with pre-trained language models. The tools perform e.g. segmentation, lemmatization and morphological tagging for Finnish texts. In addition, TurkuNPP provides information about universal dependency relations. The tools were tested with L2 Finnish learners’ texts evaluated at several CEFR levels. Only a few texts could be analysed due to various technical and other reasons. However, it was clear that the tools do not function well on learner performances, with various mistakes often confusing the processing. Typical L2 Finnish characteristics, like mixing back and front vowels (kavelin vs. kävelin), can cause incorrect lemmatization and/or tagging. However, in some cases, tools are faithful to learner language forms and are able to give the lemma based on the inflected learner language form rather than giving the targeted Finnish lemma (e.g. lumihannen → lumihansi not lumihanki). As language learning researchers have started to see learner language as a valuable language variant, this can be seen as a positive characteristic, but useful tools should give both learner language lemmas and targeted lemmas. A poster presentation of these findings was given at the annual conference of the Finnish Association of Applied Linguistics in November 2022.
In the second stage in 2023, a study has been conducted to build models for classifying learner language into CEFR levels and to investigate resources needed to establish strong deep learning based L2 Finnish research in the future. This will facilitate e.g. designing automated tools for learner language detection for pedagogical and assessment purposes and contributing to the development of textual models for Finnish. Specifically, the study investigates (1) if the currently available CEFR-annotated datasets are enough for training deep learning models, (2) how the trained models perform with new data, (3) if pretraining with MLM learner language improves model performance, and (4) if the model performs equally well across all CEFR levels.
Four CEFR annotated written Finnish as a second or foreign language datasets were used: International Corpus of Learner Finnish (ICLFI), The Advanced Finnish Learner’s Corpus (LAS2), and two young learner corpora from the cross-sectional Cefling and the longitudinal Topling projects.
The state-of-the-art Finnish BERT model, FinBERT base was used and tested against FinBERT large. To inspect the effect of pretraining (with masked language modeling (MLM) objective, models trained with and without pretraining were compared. The models were evaluated with test data extracted from all four datasets. The evaluation metrics include accuracy, F1-score, recall and precision. For model evaluation, an average value over five folds for each evaluation metric is computed. An article based on the study is currently in preparation.
Sirkku Kronholm & Ari Huhta: Automaattisten tekstityökalujen kehittäminen oppijankieliseen aineistoon. Poster presentation. AFinLA autumn symposium. Helsinki. 27.-29.10.2022. https://www.helsinki.fi/assets/drupal/2022-10/AFinLA2022_FINALFINAL_Timetable_A3.pdf
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 4.1: Report on R/Python module
Date of reporting: 22-11-2023
Report author: Julia Matveeva (University of Turku), Leo Lahti (University of Turku)
Contributors: Pyry Kantanen (University of Turku), Akewak Jeba (University of Turku)
Deliverable location: https://github.com/fennicahub/fennica
The Fennica-R package is publicly accessible at https://github.com/fennicahub/fennica. See the package README for an up-to-date link to outputs generated by the package.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 3.5: Report on Text network analysis of political texts
Date of reporting: 22-11-2023
Report author: Kimmo Elo (University of Turku)
Contributors: Kimmo Elo, Veronika Laippala, Otto Tarkka, Pyry Kantanen, Markus Korhonen (all from the University of Turku)
Deliverable location:
Both URLs will be opened for public use on December 19, 2023.
The WP’s main objective was to develop tools based on network analysis for the analysis of political texts. The following two (2) tools are now available for public use (as beta releases, see below):
The dataset these deliverables are based on covers a timespan from 1990 to 2021. The WP 3.5 uses a tailored FinParl corpus consisting of all plenary speeches of the Finnish eduskunta since 1907. The data and apps are located on data servers of the University of Turku.
Overall, the WP 3.5 has reached its most central objectives and succeeded in creating a well-functioning, active, multi-disciplinary collaboration network within the University of Turku. This network brings together expertise from social sciences and computational linguistics and is well capable of developing tools for a wide audience. The team dynamics is at good level and regular internal meetings are used to discuss current issues, problems, and solutions.
The deliverables to be published in December 2023 should be, however, considered as project milestones only. From 2024 onwards the future development of both tools will continue within the FIRI consortium project “LAWPOL”. The next milestone is Q2/2024, until which these tools are expected to be fully integrated in the first release of LAWPOL Digital Workbench for Political and Legal Studies bringing together most important political materials related to Finnish democracy.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 3.3: Report on R package for data concept network
Date of reporting: 2023-11
Report author: Maria Valaste (University of Helsinki)
Contributors: Adeline Clarke (University of Helsinki), Ida Toivanen (University of Jyväskylä), Jani-Matti Tirkkonen (University of Eastern Finland), Jaakko Peltonen (Tampere University)
Deliverable location: Several repositories in Github are published (see below).
The aim of WP3.3 is to enhance the utilization of unstructured qualitative textual in the context of Finnish surveys with the use of a concept network tool. The purpose of this toolbox is to build a bridge from not-very-NLP-coding-apt social science researchers towards the computational NLP community’s text analytics methods and processes that might be useful for understanding the results of their survey.
This deliverable is R package, which brings together tools for Finnish-language data for open-ended question analysis. In addition to the analysis tools, the R package contains a sample dataset to familiarise the user with the functions of the package. This has been built on the basis of the previous deliverable 3.3.1.
https://github.com/DARIAH-FI-Survey-Concept-Network (public)
https://github.com/DARIAH-FI-Survey-Concept-Network/finnishsurveytext (will be published)
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 3.2: Report on annotation & analysis tools for NARC data
Date of reporting: 08-11-2023
Report authors: Venla Poso (University of Jyväskylä), Ida Toivanen (University of Jyväskylä), Tanja Välisalo (University of Jyväskylä), Antero Holmila (University of Jyväskylä)
Deliverable location: Released soon.
Named entity recognition (NER) model for state authority archival data.
The National Archives of Finland started a mass digitisation project in 2019, where the aim is to digitise over 135 kilometres of archival data. We identified a need for an advantaged information extraction method from unstructured and noisy text, which will make data more accessible and potentially generate innovative uses of the data in the research sector. The process included two questionnaires to the end-users, creation of annotation guidelines, manual annotation, inter-annotator agreement testing and model development.
This process resulted in a NER model, which identifies ten different entity categories (person, organisation, date, location, geopolitical location, nationalities/religious and political groups, event, product, journal number and Finnish business identity code). Journal number and Finnish business code are newly established named entities derived from the responses to two questionnaires, as opposed to the others which rely on existing NER models. The model obtains comparable results with non-OCR’d data while significantly improving named entity recognition results when tested with OCR’d state authority archival data.
Development was conducted in cooperation with the National Archives of Finland and their DALAI project.
Version 0.1: https://huggingface.co/Kansallisarkisto/finbert-ner
Poso, Venla, Tanja Välisalo, Ida Toivanen, Antero Holmila, and Jari Ojala. 2023. “Untapped Data Resources. Applying NER for Historical Archival Records of State Authorities”. Digital Humanities in the Nordic and Baltic Countries Publications 5 (1). Oslo, Norway: 55-69. DOI: 10.5617/dhnbpub.10650
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 2.4: Report on Initializing terminology collection
Date of reporting: 2023-11
Report author: Harri Kettunen (UHEL)
Contributors: Tiina Onikki-Rantajääskö (UHEL)
Deliverable location: The Helsinki Term Bank for the Arts and Sciences – Tieteen termipankki
Since the start of 2023, 613 new concept pages have been created at the Helsinki Term Bank for the Arts and Sciences (HTB) in the following fields: Archaeology, Botany, Classical Studies, Environmental Sciences, Geology, Geophysics, History, Language Technology, Linguistics, Literary Studies, Martial Arts Studies, Media And Communication Studies, Mesoamerican Studies, North American Studies, Nutritional Sciences, Open Science, Philosophy, Religion Studies, Semiotics, and Theology.
Furthermore, updates have been made to the database on 1,806 concept pages in the following fields: Aesthetics, Archaeology, Art History, Astronomy, Behavioral Sciences, Biology, Botany, Classical Studies, Clean Energy Research, Digital Humanities, Educational Sciences, Environmental Sciences, Epidemiology, Folklore, Food Sciences, Geology, Geophysics, Heritage Research, History, Language Technology, Language Technology, Law, Linguistics, Literary Studies, Martial Arts Studies, Media And Communication Studies, Mesoamerican Studies, Microbiology, Mycology, North American Studies, Open Science, Philosophy, Seismology, Semiotics, Språkvetenskap, Study Of Religions, Sustainability Science, Terminologiako Bankos, Terminology, Theology, Translation Studies, Veterinary Medicine, and Zoology.
In addition, the fields of Anthropology, Contaminated Land Studies, Gender Studies, Mathematics, and Urban Studies are working offline until there is a critical mass of terminology to be published at the HTB. Furthermore, terminology work has been agreed upon to be carried out in the following fields: Arctic Research, Asian Studies, Geography, Military Sciences, and Physiology. A multidisciplinary group has also been established for meta scientific terminology of transdisciplinarity.
All in all, 613 new new concept pages have been created and 1,806 existing concept pages have been updated. Since the beginning of the year, the volume of the new additions and edits totals 341,175 bytes, which is approximately 280,000 characters, which translates to ca. 100 A4-size pages. The full amount of concept pages as of November 26, 2023, is 45,010.
Project: FIN-CLARIAH
Grant agreement: Academy of Finland no. 345610
Start date: 01-01-2022
Duration: 24 months
WP 2.3: Report on Aligning and retrieving
Date of reporting: 13-11-2023
Report author: Jack Rueter, Erik Axelson (University of Helsinki)
Contributors: Aleksei Ivanov (University of Tartu), Niko Partanen (University of Helsinki)
Deliverable location: Christmas Gospel text-to-speech in four Uralic languages
The «Christmas Gospel text-to-speech in four Uralic languages» (shortname: xmas-gospel-tts) is a collection of .txt, .wav and .vrt files with a variety of alignments used in Korp searches. The collection is intended as a demo for showing how to donate and implement in parallel multi-lingual spoken materials to the Language Bank of Finland.
A model for Massively Multilingual Speech (MMS, CC-BY-NC 4.0) has recently been developed at Facebook (Meta), with language support for hundreds of languages whose automatic speech recognition (ASR), text to speech (TTS) and language identification (LID) coverage is documented here.
The documentation at Meta includes 16 of approximately 32 Uralic languages or language forms spoken today. We chose three languages, Komi-Zyrian (kpv), Karelian (krl) and Erzya (myv), of the eight Uralic languages with coverage for the three categories of ASR, TTS and LID, and then we selected one additional language, Olonets-Karelian (olo, aka Livvi), one of the 16 languages lacking coverage for any of the three categories. Our choice of a fourth language was motivated by the fact that Karelian and Olonets-Karelian share much the same character-to-sound correlation and that the latter might actually be the source of digital information under the umbrella term Karelian.
The .txt files represent a segment of an existing parallel corpus, Parallel Biblical Verses for Uralic Studies (PaBiVUS), which is described in Metashare with a CC-BY-NC license. The segment or mini parallel corpus here is the Christmas Gospel (Luke 2:1–20), which is well known in Finland.
The .wav files have been produced as a text-to-speech exercise with a Python script by Aleksei Ivanov, Niko Partanen and Jack Rueter, utilizing the model for MMS built at Facebook (see above).
The .vrt files contain morpho-syntactically annotated versions of the Christmas Gospel texts, which have been subsequently inspected and manually corrected. The annotation used analysers built with Helsinki Finite-State Technologies (HFST) under continual development at Saami Language Technology (GiellaLT), based at the Norwegian Arctic University, in Tromsø: (Erzya; Komi-Zyrian; Karelian; Olonets-Karelian); Constraint Grammar (CG) methods as documented at the University of Southern Denmark, and a Universal Dependencies tool, Annotatrix.
The demo provides two facets of searchability on the Korp server. First, there is parallel corpus searchability, as found in the PaBiVUS corpus, i.e., there are links between .vrt coded verses of the Christmas Gospel with automatically annotated and subsequently manually corrected dependencies. Second, the text content of each verse is linked with the sound file (.wav), which allows for a sentence-to-utterance alignment as found, for example, in the Finnish Parliament materials, where timestamps would be the equivalents of our verse identifiers.
Last modified on 2023-11-30



