
Tässä oppaassa käytetään komentorivityökaluja melko haastavaan tehtävään: videotiedoston (joka voi sisältää puheen lisäksi hiljaisuutta, musiikkia ja muita ääniä) automaattiseen tekstittämiseen. Työkaluina toimivat
ffmpeg, joka on monikäyttöinen videon, äänen ja multimedian käsittelyyn tarkoitettu ohjelmistoopenSMILE, joka on äänidatan signaalikäsittelyyn tarkoitettu ohjelmisto, jota käytetään erityisesti puheen ja musiikin piirteiden analysointiinffmpegin käyttöönottoJos työskentelet CSC:n laskentaympäristössä, ffmpegin pitäisi löytyä valmiiksi asennettuna ottamalla käyttöön sopivan moduulin komennolla
module load ffmpeg
Muussa tapauksessa voit lukea sen asennusohjeita täältä.
ffmpeg:lläEnsin luodaan äänitiedosto, joka sisältää videotiedoston ääniraidan. Koska kyse on puheentunnistuksesta, monikanavainen ääni ei tässä meitä kiinnosta, vaan tyydymme mono-ääneen.
Sen sijaan audioformaatti on meille merkityksellisempi asia. Ääntä käsittelevät ohjelmat yleensä ottaen olettavat saavansa pakkaamatonta äänidataa, kun taas useimmissa videotiedostoissa on pakattua ääntä. Jos sinulla sattuu olemaan käytettävissäsi myös pakkaamaton ääniraita, kannattaa käyttää sitä, mutta muussa tapauksessa ffmpeg:llä saa videotiedostosta ulos äänen pakkaamattomassa formaatissa (vaikka toki pakkaamisesta kärsineenä) tällä komennolla:
ffmpeg -i input_video_file -vn -ac 1 -acodec pcm_s16le output_audio.wav
-i nimeää ffmpeg:lle syötteenä annettavan videotiedoston-vn kertoo ffmpeg:lle “ei käytetä videoraitaa”-ac 1 kertoo ffmpeg:lle “yksi ääniraita”. Jos alkuperäinen ääni on monikanavaista, se miksataan monoääneksi. HUOM: Jos videossa on useampi ääniraita, joissa on eri sisältö, voit valita niistä oikean optiolla -map 0:a:n, joka kuvaa n:nnen äänikanavan numeroki 0, joka sitten kirjoitetaan tulostiedostoon.-acodec pcm_s16le määrittää käytetyn dataformaatin. Tässä tapauksessa PCM (Pulse Code Modulation) etumerkillinen (signed) 16-bittinen nousevalla tavujärjestyksellä (little-endian). Yksityiskohtat eivät ole niin olennaisia, mutta tuloksena pitäisi olla audiokäsittelyohjelmille laajasti yhteensopiva .wav tiedosto.output_audio.wav on tulostiedoston nimiTuloksena on yksi iso (videon mittainen) äänitiedosto, mahdollisesti hankalan pitkä käsiteltäväksi yhtenä pätkänä puheentunnistusohjelmassa. Seuraavassa vaiheessa poistamme siitä kaiken muun paitsi puheen, ja pätkimme sen vuoroihin (turns), eli jaksoihin joiden välillä puhuja vaihtuu tai pitää taukoa.
config/ ja scripts/OpenSMILE-ohjelmiston komentorivikäsky, jota tässä oppaassa käytämme, on SMILExtract. Jos työskentelet CSC:n laskentaympäristössä, OpenSMILEn pitäisi löytyä valmiiksi asennettuna ottamalla käyttöön sopivan moduulin komennolla
module load openSMILE
Muussa tapauksessa voit perehtyä OpenSMILEn asennusohjeisiin täällä.
OpenSMILE -ohelmistojakelun osana tulee myös config/ -hakemisto, joka sisältää määrittelyitä erilaisten piirteiden tunnistamiseen äänitiedostoista. Näiden tarkoituksena on olla hyödyksi korkeamman tason tehtävissä, esimerkiksi puhujan tunnetilan tunnistamisessa. Samoin osana ohjelmistoa on scripts/ -hakemisto, jossa on kokonaisia yksittäisen tehtävän alusta loppuun tekemiseen tarkoitettuja skriptejä ja apukeinoja. CSC:n laskentaympäristössä näiden hakemistojen sijainti on saatavissa ympäristömuuttujissa $OPENSMILE_CONFIG ja $OPENSMILE_SCRIPTS. Tässä tapauksessa käytämme hakemistossa $OPENSMILE_SCRIPTS/vad/ (VAD = Voice Activity Detection, puheäänen tunnistus) olevaa koodia. Hakemiston README-tiedosto:
This is meant as an example to show how to implement such
a VAD in openSMILE with the RNN components and to provide
a simple VAD for prototype development. The noise-robustness
of this VAD is *not* state-of-the-art, it has been built on
a small-scale research data-set, mainly for clean speech.
...
If you need a more accurate and noise-robust VAD,
contact audEERING at info@audeering.com for a demo of
our latest commercial VAD technology.
Eli saavutettavissa on hyvä tulos, kunhan ääni ei ole liian kohinaista, ja jos haluamme myöhemmin korvata puheäänitunnistuksen kaupallisella tuotteella, pystymme toivon mukaan uudelleenkäyttämään siihen tässä tehtävää työtä.
scripts/vad sisältää kaksi skriptiä; vad_opensource.conf, joka tuottaa puheäänen aktiivisuutta kuvaavan numeerisen arvon jokaiselle lyhyelle (oletuksena 0,025 sekuntia) äänijaksolle (audio frame), ja vad_segmenter.conf, joka tuottaa varsinaisia puheääntä sisältäviä .wav -tiedostoja.
Skripteillä on riippuvuuksia muihin samassa hakemistossa oleviin tiedostoihin, joten niitä suorittaessa pitää olla komentorivillä kyseisessä vad/ -hakemistossa. Jos sinulla ei ole jo valmiiksi hakemistoa jossain käytettävissä, voit kloonata openSMILEn Git-versiointijärjestelmästä ja vaihtaa oikeaan alihakemistoon näin:
$ cp -r $OPENSMILE_SCRIPTS/vad .
$ cd vad
($ -merkit tarkoittavat komentokehotetta, eli tässä on kaksi erillistä komentoa.)
vad_segmenter voi kirjoittaa vain audiosegmentit jos et tarvitse muuta, mutta se voi samalla tuottaa aikaleimatut luettelut segmenteistä ja raakadatan puheääniaktivaatiosta, jota se käyttää puheosuuksien eristämiseen. Saamme tuotettua ne kaikki samalla kertaa näin:
$ SMILExtract -C vad_segmenter.conf -I /path/to/audio.wav \
-waveoutput /path/to/speech_segment -csvoutput /path/to/vad_data.csv \
-saveSegmentTimes /path/to/segments.csv
Huomioita:
/path/to/ -I-option jälkeen pitää olla se hakemisto, jossa lähteenä oleva äänitiedostosi sijaitsee.-waveoutput on etuliite, eli tässä tapauksessa äänitiedostoilla on nimet tyyliin speech_segment_0001.wav, polkuna annetun hakemiston sisällä.vad_data.csv sisältää rivejä tähän tyyliin:
0.000000;-5.076322e-01
0.010000;-6.303211e-01
ja niin edelleen. Ensimmäinen sarake on aikaleima, ja toinen puheäänen aktivaation määrä. Tätä voi kokeilla tarkastella esim. gnuplotilla (tai vaikka taulukkolaskentaohjelmalla):
$ gnuplot
gnuplot> set datafile separator ';'
gnuplot> set xlabel 'Time (s)'
gnuplot> plot 'vad_data.csv' using 1:2 with lines title 'Voice activity'
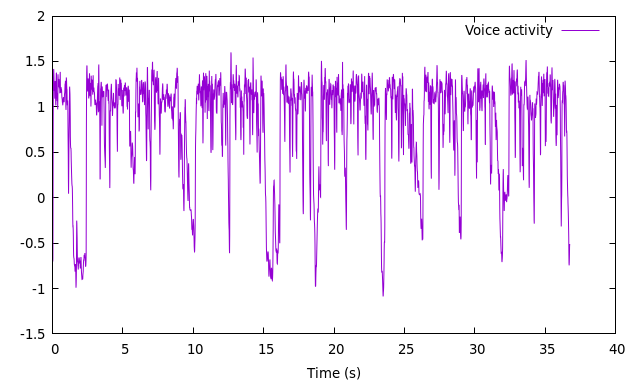
(Tässä oli kyseessä lyhyt äänitiedosto joka sisältää vain puhetta ja lyhyitä taukoja.)
segments.csv listaa pätkityt äänitiedostot, alku- ja loppuajat, sekä niiden väliin mahtuvien ääninäytteiden lukumäärät::
output_segment_0001.wav;1.000000,1.430000;70
output_segment_0002.wav;2.400000,9.740000;761
output_segment_0003.wav;10.150000,15.170000;529
output_segment_0004.wav;15.700000,36.680000;2107
Ilmeisesti puheäänen aktiivisuutta tunnistava alustus toimii openSMILEn ilmaisessa moduulissa niin, että aivan äänitiedoston alussa oleva puhe voi jäädä merkkaamatta. Tämän harmillisen ongelman voi kiertää
output_segment_0001.wav. Hae ensimmäisen segmentin lopetusaika tiedostosta segments.csv (esim. 2.430000) ja käytä ffmpeg:tä äänen leikaamiseen alusta tuohon aikaleimaan asti komennolla ffmpeg -i output_audio.wav -t 2.43 -acodec copy output_segment_0001.wav.ffmpeg -f lavfi -t 1 -i anullsrc=channel_layout=mono:sample_rate=44100 -i output_audio.wav -filter_complex "[0:a][1:a]concat=n=2:v=0:a=1" output_audio_with_silence.wavlavfi on ffmpeg:n käyttämä “virtuaalinen sisääntulo” ja anullsrc on “nollalähde”, ja nämä yhdistetään alkuperäiseen ääneen filter_complexin concat– eli konkatenaatiotoiminnolla.Oppaan tässä osuudessa käytämme Kielipankin omaa suomenkielistä puheentunnistuspalvelua, mutta se on vain yksi monesta vaihtoehdosta. Kyseinen palvelu on toistaiseksi julkisesti ja vapaasti käytettävissä, mikä voi tulevaisuudessa muuttua. Muiden, myös paikallisesti ajettavien ohjelmistojen käyttäminen (esim. Whisper on hyvin samantyyppistä.
API-dokumentaation perusteella voit ohjelmoida puheentunnistusprosessin itse haluamallasi ohjelmointikielellä. Esimerkiksi, kun segmenttien nimet ja ajat on saatu luettua, tämä Python-pätkä:
base_url = "https://kielipankki.rahtiapp.fi/audio/asr/fi"
submit_url = base_url + "/submit_file"
query_url = base_url + "/query_job"
response = requests.post(
submit_url,
files={"file": (audio_segment_filename, open(path_to_audio_segment, "rb"))},
)
response_dict = json.loads(response.text)
while True:
time.sleep(1)
query_response = requests.post(query_url, data=response_dict["jobid"])
query_response_dict = json.loads(query_response.text)
is_pending = (
"status" in query_response_dict
and query_response_dict["status"] == "pending"
)
incomplete = (
"done" in query_response_dict and query_response_dict["done"] == False
)
if is_pending or incomplete:
continue
else:
break
for segment in query_response_dict["segments"]:
# these are segments from the ASR endpoint, not our segments
duration = float(segment["duration"])
transcript = segment["responses"][0]["transcript"]
Lähettää audiotiedostoja ASR-palveluun ja palauttaa luettelon lyhyempiä pätkiä pituuksineen ja transkriptioineen.
Yleisin tekstitystiedostotyyppi .srt, joka koostuu numeroidusta luettelosta tekstitysruutuja tähän tapaan:
1
00:00:01,000 --> 00:00:05,500
Tämä on ensimmäinen tekstitysruutu, se alkaa näkyä yhden sekunnin kohdalla.
2
00:01:23,000 --> 00:01:33,300
Tämä on toinen tekstitysruutu. Sitä edeltää pitkä hiljaisuus.
Muodossa hours:minutes:seconds,milliseconds annetut aikaleimat määräävät, milloin ja miten pitkään tekstitys näkyy.
.srt -skriptiEsimerkinomainen skripti löytyy täältä. Sitä voi käyttää näin (tuloste menee stdoutiin, eli suoraan terminaaliin, josta sen voi uudelleenohjata tiedostoon):
$ python write_srt_from_audio_segments.py --segment-file segments.csv
1
00:00:02,400 --> 00:00:09,996
pohjantuuli ja aurinko väittelivät kummalla olisi enemmän voimaa kun he samalla näkivät kulkijan jolla oli yllään lämmin takki
2
00:00:10,150 --> 00:00:15,430
silloin he sopivat että se on voimakkaampi joka nopeammin saa kulkijan riisumaan takkinsa
3
00:00:15,700 --> 00:00:23,407
pohjantuuli alkoi puhaltaa niin että viuhuu mutta mitä kovemmin se puhalsi sitä tiukemmin kääri mies takin ympärilleen
Yleensä videodata sisällytetään ns. säiliötiedostoon (container format), jossa on oma säilytystapansa mm. useammalle ääniraidalle, tekstitysraidoille ja metadatalle. Riippuen käyttämästäsi säiliötiedostotyypistä, on erilaisia tapoja tallentaa niihin tekstitysraitoja. Tässä käsittelemme niistä kaksi yleisintä. Lisäksi on mahdollista (mutta hyvin harvoin suositeltavaa) kirjoittaa tekstitys suoraan videokuvan päälle.
Tämä tiedostotyyppi, jonka pääte on yleensä .mkv, tukee suoraan .srt -muotoa, joten sen sisällyttäminen on suoraviivaista. Yhden video- ja ääniraidan tapauksessa, tämä komento:
$ ffmpeg -i input_video.mkv -i subtitles.srt -c:v copy -c:a copy \
-c:s srt output_video.mkv
tuottaa halutun tulostiedoston, jonka tekstiraita on tiedoston subtitles.srt mukainen.
Useamman kielen ja tekstiraidan tapauksessa ffmpeg osaa myös kirjoittaa ne metadatoineen yhdellä komennolla:
ffmpeg -i input_video.mkv -i english_subtitles.srt -i spanish_subtitles.srt \
-i french_subtitles.srt -map 0 -map 1 -map 2 -map 3 -c:v copy -c:a copy \
-c:s srt -metadata:s:s:0 language=eng -metadata:s:s:1 language=spa \
-metadata:s:s:2 language=fre output_video.mkv
kirjoittaa englannin-, espanjan- ja ranskankieliset tekstiraidat.
.mp4Näihin ffmpeg osaa kirjoittaa mov_text -tyyppiset tekstiraidat (joita jälleen voi olla useampi kappale). Yhden raidan tapauksessa
$ ffmpeg -i input_video.mp4 -i subtitles.srt -c:v copy -c:a copy -c:s mov_text \
-metadata:s:s:0 language=fin output_video.mp4
kirjoittaa suomenkielisen tekstiraidan.
Lähes aina kannattaa käyttää ylläolevan kaltaisia container-tiedostojen tekstitystoimintoja, koska tällöin alkuperäinen videodata säilyy muuttumattomana, tekstityksen voi panna päälle tai pois, ja tekstitys voi olla monikielinen. Joissain poikkeustapauksissa voi kuitenkin olla tarpeen tuottaa tekstit suoraan videokuvan päälle.
ffmpegillä on suodin (filter) nimeltään subtitles, jolla voi kirjoittaa mielivaltaiseen videotiedostotyyppiin tekstit suoraan kuvan päälle käyttäen .srt -lähdettä:
ffmpeg -i input_video.mp4 -vf "subtitles=subtitles.srt" -c:a copy output_video.mp4
Kielipankilla on Reittidemo-niminen aineisto, jota käytetään esimerkkinä ja testaamista varten. Nyt käsitellyillä työkaluilla voidaan kokeilla, millaiset tekstitykset siihen saadaan.
Ensin haetaan aineisto omalle koneelle ja puretaanzip-paketti.
$ wget https://www.kielipankki.fi/download/reittidemo/reittidemo.zip
$ unzip reittidemo.zip
$ cd reittidemo
Hakemistossa on videotiedosto, reittidemo.mp4, äänitiedosto reittidemo.wav sekä annotaatio- ja metadatatiedostot .eaf ja .imdi. Saisimme korkelaatuisen ja kielitieteellisesti informoidun tekstityksen annotaatiotiedostosta, mutta katsotaan, miltä suora ASR-transkriptio näyttää. Voimme kokeilla tehdä sen sekä pakkaamattomasta äänilähteestä että pakatusta videon ääniraidasta.
$ ffmpeg -i reitti_a-siipeen.mp4 -vn -ac 1 -acodec pcm_s16le reitti_a-siipeen_pakattu.wav
$ # Tehdään alihakemistot joihin kirjoitetaan väliaikais- jä tulostiedostoja
$ mkdir pakkaamaton
$ mkdir pakattu
$ cd ~/opensmile/scripts/vad
$ SMILExtract -C vad_segmenter.conf -I ~/reittidemo/reitti_a-siipeen.wav \
-csvoutput ~/reittidemo/pakkaamaton/vad.csv \
-saveSegmentTimes ~/reittidemo/pakkaamaton/segments.csv \
-waveoutput ~/reittidemo/pakkaamaton/segment_
SMILExtractin tulosteen pitäisi näyttää jotakuinkin tältä:
(MSG) [2] SMILExtract: openSMILE starting!
(MSG) [2] SMILExtract: config file is: vad_segmenter.conf
(MSG) [2] cComponentManager: successfully registered 102 component types.
(WRN) [1] instance 'turn': readVad=1, and threshold2 set to a value which looks like log- or rms-energy thresholds!
You should remove the threshold option, or consider that you are setting the VAD threshold with it!
(WRN) [1] instance 'turn': readVad=1, and threshold set to a value which looks like log- or rms-energy thresholds!
You should remove the threshold option, or consider that you are setting the VAD threshold with it!
(MSG) [2] instance 'mvnVAD': Loading init file in old MVN binary format
(MSG) [2] smileRnn: Net file format: 1
(MSG) [2] smileRnn: [rnn] net-task: 1
(MSG) [2] cComponentManager: successfully finished createInstances (15 component instances were finalised,
1 data memories were finalised)
(MSG) [2] cComponentManager: starting single thread processing loop
(MSG) [2] instance 'mvnVAD': nFrames initialised to 0
(MSG) [2] cComponentManager: Processing finished! System ran for 6351 ticks.
Sitten tehdään sama pakatulle äänelle, eli sama komento, mutta äänitiedosto on reitti_a-siipeen_pakattu.wav ja alihakemistoina aina pakattu/.
Jo nyt näkyy eroja: pakkaamattoman äänen segmentointi tuotti 11 segmenttiä, ja pakatun äänen segmentointi 7 segmenttiä. Pakkaamattoman äänen segmenttien kokonaispituus on kuitenkin hieman lyhempi. Molemmat ovat merkinneet alkuyskäisyn omaksi puhesegmentikseen, ja sana “tuolta” jää omaksi fragmentikseen (pakkaamattoman äänen segmentoinnissa sample_0008.wav). Myöskään vuoronvaihtelut eivät tule mitenkään moitteettomasti tunnistettua.
Seuraavaksi tehdään puheentunnistus käyttäen aiemmin mainittua esimerkkiskriptiä:
$ python write_srt_file_from_audio.py --segment-file ~/reittidemo/pakkaamaton/segments.csv > ~/reittidemo/pakkaamaton/reittidemo.srt
ja
$ python write_srt_file_from_audio.py --segment-file ~/reittidemo/pakkaamaton/segments.csv > ~/reittidemo/pakattu/reittidemo.srt
Tekstitystiedostoja lukemalla huomaa, että tässä tapauksessa puhekielisyys ja nopeat vuoronvaihdot olivat puheentunnistimelle liikaa, ja tekstityksessä on paljon korjattavaa. Sitä voi kuitenkin onneksi tehdä käsin.
Tekstitetyn videon voi tuottaa komennolla
$ cd ~/reittidemo
$ ffmpeg -i reitti_a-siipeen.mp4 -i pakkaamaton/reittidemo.srt -c:v copy -c:a copy -c:s mov_text \
-metadata:s:s:0 language=fin reitti_a-siipeen_tekstitetty.mp4




