
This page describes the contents of a VRT formatted document in simple terms, e.g., for a user who downloads and needs to use resources in VRT format. We refer here to the VRT format as used in the Language Bank of Finland, as others may have slightly different conventions.
VRT (VeRticalized Text) is the input format for the IMS Open Corpus Workbench (CWB) software underlying Korp. VRT is a token-oriented columnar text format: each token (word) is on its own line together with its possible annotation attributes (positional attributes), such as lemma, part of speech, morphological analysis and syntactic relation, separated by tabs. The structure of the text is represented with XML-style tags on their own lines. Start tags may contain XML-style attributes for the structure (structural attributes), which may vary between corpora. In contrast to XML, VRT does not require a single root element (structural attribute), so a VRT input may consist of a sequence of texts, for example.
(There is another, more technical description of VRT documents for internal use and for resource depositors at https://www.kielipankki.fi/development/korp/corpus-input-format/.)
The data at the character level:
Example of VRT format:
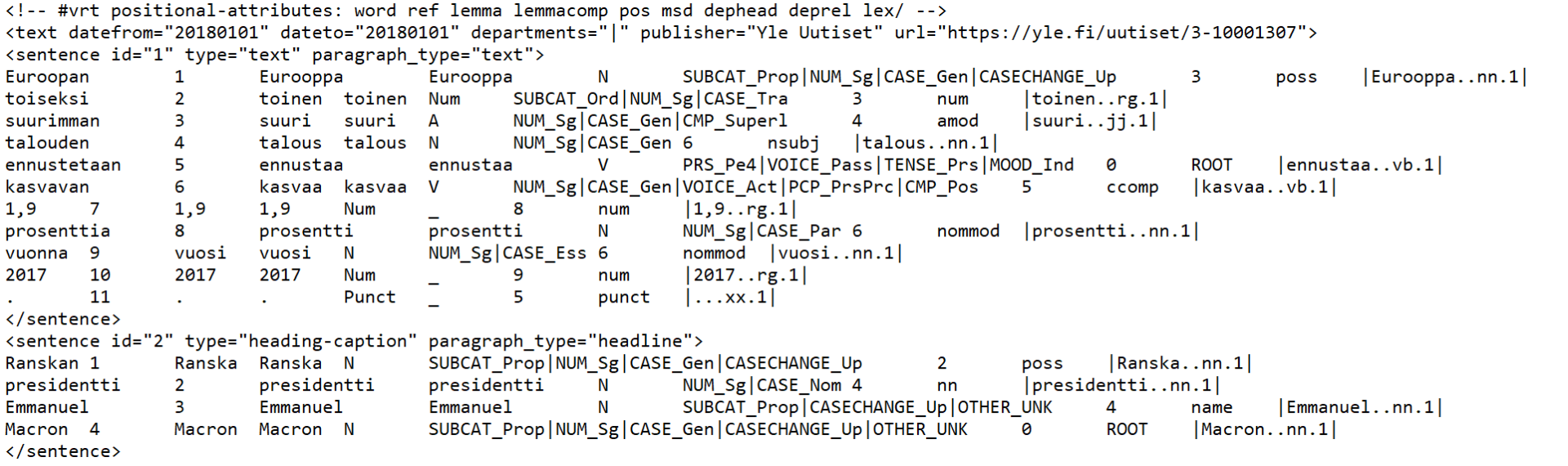
Structural elements are typically text, paragraph and sentence . Not all corpora have the paragraph level, though, and corpora can also have other structures, such as clause or ne (named entity).
The positional attributes (given in the first line of the VRT file as a comment) are often the following:
An attribute may have multiple values. A multi-valued attribute is represented by separating the values by vertical bars and adding vertical bars at the beginning and end of the whole value; for example, |Adj|Noun|Verb|. The name of a multi-valued positional attribute is suffixed with a slash in the positional attributes comment line. An empty feature set attribute value (no values in the set) is denoted by a single vertical bar.
VRT files may contain additional comment lines beginning with <!--? VRT extracted from Korp CWB data has a couple of such lines at the beginning and end of each file.
This page has a persistent identifier: urn:nbn:fi:lb-2023020121



